Puede utilizar Conexiones de red para crear varios tipos de conexiones entre equipos. En la tabla siguiente se muestra cada tipo de conexión que puede crear, los métodos de comunicación que puede utilizar para crear dichos tipos y un ejemplo de cada uno de ellos. Para obtener más información, haga clic en el tipo de conexión apropiado en la tabla.
Tipo de conexiónMétodo de comunicaciónEjemplo
Conexiones de acceso telefónico
Módem, ISDN, X.25
Conectar a una red privada o a Internet mediante acceso remoto.
Conexiones de red privada virtual (VPN)
Conexiones VPN a redes de organizaciones a través de Internet mediante PPTP o L2TP
Conectar de forma protegida con una red privada a través de Internet
Kit de administración de Connection Manager
Consulte conexiones de acceso telefónico o VPN
Conectar con una red privada mediante una configuración de acceso telefónico o VPN suministrada por el administrador de la red en un perfil de autoinstalación
Utilizar conexiones de área local
Ethernet, Token Ring, módem por cable, DSL, FDDI, IP sobre ATM, IrDA, comunicaciones inalámbricas, tecnologías WAN (T1, Frame Relay), PPPoE
Conectar directamente a una red de área local, al módem por cable o al módem DSL a través de un adaptador Ethernet o un dispositivo similar
Utilizar conexiones directas
Cable serie, vínculo de infrarrojos, cable DirectParallel
Conectar un equipo de mano que ejecuta Microsoft® Windows® CE a un equipo de escritorio para sincronizar información
Conexiones entrantes
Consulte conexiones de acceso telefónico, VPN o directas
Aceptar conexiones de acceso telefónico, VPN o directas de otros equipos
http://technet.microsoft.com/es-es/library/cc780142(WS.10).aspx
jueves, 17 de noviembre de 2011
Topología de redes
Qué es la topología de una red
La topología de una red es el arreglo físico o lógico en el cual los dispositivos o nodos de una red (e.g. computadoras, impresoras, servidores, hubs, switches, enrutadores, etc.) se interconectan entre sí sobre un medio de comunicación.
a) Topología física: Se refiere al diseño actual del medio de transmisión de la red.
b) Topología lógica: Se refiere a la trayectoria lógica que una señal a su paso por los nodos de la red.
Existen varias topologías de red básicas (ducto, estrella, anillo y malla), pero también existen redes híbridas que combinan una o más de las topologías anteriores en una misma red.
Topología de ducto (bus)
Una topología de ducto o bus está caracterizada por una dorsal principal con dispositivos de red interconectados a lo largo de la dorsal. Las redes de ductos son consideradas como topologías pasivas. Las computadoras "escuchan" al ducto. Cuando éstas están listas para transmitir, ellas se aseguran que no haya nadie más transmitiendo en el ducto, y entonces ellas envían sus paquetes de información. Las redes de ducto basadas en contención (ya que cada computadora debe contender por un tiempo de transmisión) típicamente emplean la arquitectura de red ETHERNET.
Las redes de bus comúnmente utilizan cable coaxial como medio de comunicación, las computadoras se contaban al ducto mendiante un conector BNC en forma de T. En el extremo de la red se ponia un terminador (si se utilizaba un cable de 50 ohm, se ponia un terminador de 50 ohms también).
Las redes de ducto son fácil de instalar y de extender. Son muy susceptibles a quebraduras de cable, conectores y cortos en el cable que son muy díficiles de encontrar. Un problema físico en la red, tal como un conector T, puede tumbar toda la red.

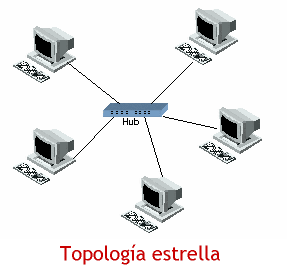
Topología de estrella (star)
En una topología de estrella, las computadoras en la red se conectan a un dispositivo central conocido como concentrador (hub en inglés) o a un conmutador de paquetes (swicth en inglés).
En un ambiente LAN cada computadora se conecta con su propio cable (típicamente par trenzado) a un puerto del hub o switch. Este tipo de red sigue siendo pasiva, utilizando un método basado en contensión, las computadoras escuchan el cable y contienden por un tiempo de transmisión.
Debido a que la topología estrella utiliza un cable de conexión para cada computadora, es muy fácil de expandir, sólo dependerá del número de puertos disponibles en el hub o switch (aunque se pueden conectar hubs o switchs en cadena para así incrementar el número de puertos). La desventaja de esta topología en la centralización de la comunicación, ya que si el hub falla, toda la red se cae.
Hay que aclarar que aunque la topología física de una red Ethernet basada en hub es estrella, la topología lógica sigue siendo basada en ducto.
Topología de anillo (ring)
Una topología de anillo conecta los dispositivos de red uno tras otro sobre el cable en un círculo físico. La topología de anillo mueve información sobre el cable en una dirección y es considerada como una topología activa. Las computadoras en la red retransmiten los paquetes que reciben y los envían a la siguiente computadora en la red. El acceso al medio de la red es otorgado a una computadora en particular en la red por un "token". El token circula alrededor del anillo y cuando una computadora desea enviar datos, espera al token y posiciona de él. La computadora entonces envía los datos sobre el cable. La computadora destino envía un mensaje (a la computadora que envió los datos) que de fueron recibidos correctamente. La computadora que transmitio los datos, crea un nuevo token y los envía a la siguiente computadora, empezando el ritual de paso de token o estafeta (token passing) nuevamente.

Topología de malla (mesh)
La topología de malla (mesh) utiliza conexiones redundantes entre los dispositivos de la red aí como una estrategía de tolerancia a fallas. Cada dispositivo en la red está conectado a todos los demás (todos conectados con todos). Este tipo de tecnología requiere mucho cable (cuando se utiliza el cable como medio, pero puede ser inalámbrico también). Pero debido a la redundancia, la red puede seguir operando si una conexión se rompe.
Las redes de malla, obviamente, son mas difíciles y caras para instalar que las otras topologías de red debido al gran número de conexiones requeridas.

http://www.eveliux.com/mx/topologias-de-red.php
La topología de una red es el arreglo físico o lógico en el cual los dispositivos o nodos de una red (e.g. computadoras, impresoras, servidores, hubs, switches, enrutadores, etc.) se interconectan entre sí sobre un medio de comunicación.
a) Topología física: Se refiere al diseño actual del medio de transmisión de la red.
b) Topología lógica: Se refiere a la trayectoria lógica que una señal a su paso por los nodos de la red.
Existen varias topologías de red básicas (ducto, estrella, anillo y malla), pero también existen redes híbridas que combinan una o más de las topologías anteriores en una misma red.
Topología de ducto (bus)
Una topología de ducto o bus está caracterizada por una dorsal principal con dispositivos de red interconectados a lo largo de la dorsal. Las redes de ductos son consideradas como topologías pasivas. Las computadoras "escuchan" al ducto. Cuando éstas están listas para transmitir, ellas se aseguran que no haya nadie más transmitiendo en el ducto, y entonces ellas envían sus paquetes de información. Las redes de ducto basadas en contención (ya que cada computadora debe contender por un tiempo de transmisión) típicamente emplean la arquitectura de red ETHERNET.
Las redes de bus comúnmente utilizan cable coaxial como medio de comunicación, las computadoras se contaban al ducto mendiante un conector BNC en forma de T. En el extremo de la red se ponia un terminador (si se utilizaba un cable de 50 ohm, se ponia un terminador de 50 ohms también).
Las redes de ducto son fácil de instalar y de extender. Son muy susceptibles a quebraduras de cable, conectores y cortos en el cable que son muy díficiles de encontrar. Un problema físico en la red, tal como un conector T, puede tumbar toda la red.
Topología de estrella (star)
En una topología de estrella, las computadoras en la red se conectan a un dispositivo central conocido como concentrador (hub en inglés) o a un conmutador de paquetes (swicth en inglés).
En un ambiente LAN cada computadora se conecta con su propio cable (típicamente par trenzado) a un puerto del hub o switch. Este tipo de red sigue siendo pasiva, utilizando un método basado en contensión, las computadoras escuchan el cable y contienden por un tiempo de transmisión.
Debido a que la topología estrella utiliza un cable de conexión para cada computadora, es muy fácil de expandir, sólo dependerá del número de puertos disponibles en el hub o switch (aunque se pueden conectar hubs o switchs en cadena para así incrementar el número de puertos). La desventaja de esta topología en la centralización de la comunicación, ya que si el hub falla, toda la red se cae.
Hay que aclarar que aunque la topología física de una red Ethernet basada en hub es estrella, la topología lógica sigue siendo basada en ducto.
Topología de anillo (ring)
Una topología de anillo conecta los dispositivos de red uno tras otro sobre el cable en un círculo físico. La topología de anillo mueve información sobre el cable en una dirección y es considerada como una topología activa. Las computadoras en la red retransmiten los paquetes que reciben y los envían a la siguiente computadora en la red. El acceso al medio de la red es otorgado a una computadora en particular en la red por un "token". El token circula alrededor del anillo y cuando una computadora desea enviar datos, espera al token y posiciona de él. La computadora entonces envía los datos sobre el cable. La computadora destino envía un mensaje (a la computadora que envió los datos) que de fueron recibidos correctamente. La computadora que transmitio los datos, crea un nuevo token y los envía a la siguiente computadora, empezando el ritual de paso de token o estafeta (token passing) nuevamente.
Topología de malla (mesh)
La topología de malla (mesh) utiliza conexiones redundantes entre los dispositivos de la red aí como una estrategía de tolerancia a fallas. Cada dispositivo en la red está conectado a todos los demás (todos conectados con todos). Este tipo de tecnología requiere mucho cable (cuando se utiliza el cable como medio, pero puede ser inalámbrico también). Pero debido a la redundancia, la red puede seguir operando si una conexión se rompe.
Las redes de malla, obviamente, son mas difíciles y caras para instalar que las otras topologías de red debido al gran número de conexiones requeridas.
http://www.eveliux.com/mx/topologias-de-red.php
Organización de redes
SIMILITUDES Y DIFERENCIAS
Tanto la red Internet como una Intranet y una Extranet, tienen en común la tecnología subyacente. Una infraestructura basada en estándares y en tecnologías que soportan el uso compartido de recursos comunes. Por infraestructura se hace referencia a la que crea, administra y permite compartir el contenido. La única restricción técnica es que la red física debe estar basada en el protocolo IP (Internet Protocol). Por lo tanto el objetivo de las tres radica en la posibilidad de compartir contenido y recursos.
Si tuviéramos que definir qué hace diferente a cada una, diríamos que Internet ofrece "teóricamente" acceso a la información a un grupo ilimitado de personas alrededor del mundo, mientras que una Intranet solo permite el acceso a información privada y recursos de una organización a aquellas personas que pertenecen a la misma o que están estrechamente relacionadas a la organización y que tiene permiso para hacer uso, sin que ello implique de ninguna forma que tienen acceso a toda la información y a todos los recursos. Las compañías están encontrando que las intranets son herramientas poderosas para automatizar procesos, incrementando la posibilidad de acceso a sistemas críticos e información importante, compartiendo las mejores prácticas, colaborando para solucionar problemas a clientes y permitiendo un alto nivel de interacción entre sus integrantes. Los beneficios de una Intranet bien implementada incluyen el incremento de la flexibilidad de la empresa, la habilidad para responder más rápidamente a las condiciones cambiantes del mercado y la habilidad de servir mejor a sus clientes.
Por último, una Extranet es una "extensión" de una Intranet, que permite el acceso no sólo al personal de la organización sino también a usuarios autorizados que sin pertenecer a ella, se relacionan a través de procesos o transacciones, como pueden ser clientes, proveedores, empresas vinculadas, etc. En un ambiente de negocios electrónicos, las empresas pueden vincular sus procesos claves para formar grupos virtuales, donde se logra un nivel de integración tan alto que es difícil decir dónde una compañía comienza y otra termina.
Para resumir un poco las diferencias que existen entre Internet, Intranet y Extranet veamos el siguiente cuadro:
http://www.gestiopolis.com/administracion-estrategia/estrategia/internet-intranets-extranets.htm
Tanto la red Internet como una Intranet y una Extranet, tienen en común la tecnología subyacente. Una infraestructura basada en estándares y en tecnologías que soportan el uso compartido de recursos comunes. Por infraestructura se hace referencia a la que crea, administra y permite compartir el contenido. La única restricción técnica es que la red física debe estar basada en el protocolo IP (Internet Protocol). Por lo tanto el objetivo de las tres radica en la posibilidad de compartir contenido y recursos.
Si tuviéramos que definir qué hace diferente a cada una, diríamos que Internet ofrece "teóricamente" acceso a la información a un grupo ilimitado de personas alrededor del mundo, mientras que una Intranet solo permite el acceso a información privada y recursos de una organización a aquellas personas que pertenecen a la misma o que están estrechamente relacionadas a la organización y que tiene permiso para hacer uso, sin que ello implique de ninguna forma que tienen acceso a toda la información y a todos los recursos. Las compañías están encontrando que las intranets son herramientas poderosas para automatizar procesos, incrementando la posibilidad de acceso a sistemas críticos e información importante, compartiendo las mejores prácticas, colaborando para solucionar problemas a clientes y permitiendo un alto nivel de interacción entre sus integrantes. Los beneficios de una Intranet bien implementada incluyen el incremento de la flexibilidad de la empresa, la habilidad para responder más rápidamente a las condiciones cambiantes del mercado y la habilidad de servir mejor a sus clientes.
Por último, una Extranet es una "extensión" de una Intranet, que permite el acceso no sólo al personal de la organización sino también a usuarios autorizados que sin pertenecer a ella, se relacionan a través de procesos o transacciones, como pueden ser clientes, proveedores, empresas vinculadas, etc. En un ambiente de negocios electrónicos, las empresas pueden vincular sus procesos claves para formar grupos virtuales, donde se logra un nivel de integración tan alto que es difícil decir dónde una compañía comienza y otra termina.
Para resumir un poco las diferencias que existen entre Internet, Intranet y Extranet veamos el siguiente cuadro:
Internet | Intranet | Extranet | |
Acceso | Público | Privado | Semi-público |
Usuarios | Cualquiera | Miembros de una compañía | Grupo de empresas estrechamente relacionadas |
Información | Fragmentada | Propietaria | Compartida dentro de un círculo de empresas |
http://www.gestiopolis.com/administracion-estrategia/estrategia/internet-intranets-extranets.htm
miércoles, 16 de noviembre de 2011
Tipos de Comunicación entre redes
Simétrica
Todos los procesos pueden enviar o recibir. También llamada bidireccional para el caso de dos procesos.
Asimétrica
Un proceso puede enviar, los demás procesos solo reciben. También llamada unidireccional. Suele usarse para hospedar servidores en Internet.
Síncrona
Quien envía permanece bloqueado esperando a que llegue una respuesta del receptor antes de realizar cualquier otro ejercicio.
Asíncrona
Quién envía continúa con su ejecución inmediatamente después de enviar el mensaje al receptor.
Fuente: http://es.wikipedia.org
Redes de Pares
Las redes de pares, también conocidas como P2P (por la sigla de su nombre en inglés “Peer to Peer”), son grandes protagonistas de este tiempo. No pasan muchas semanas sin que alguna de estas redes o sus usuarios aparezcan en los diarios de tirada masiva como la gran amenaza de las industrias del entretenimiento. Es que las redes de pares se han convertido en herramientas fáciles de usar, accesibles y muy dúctiles para compartir cultura. En consecuencia, son las redes que la gente usa para intercambiar archivos de todo tipo.
"En las redes P2P se establece una conexión directa entre usuarios, donde cualquier nodo puede transmitir información al mismo tiempo que la recibe."
Una red P2P se forma a partir de la interconexión entre pares (peers). En otras palabras, en una red P2P los participantes no asumen roles separados como “clientes” y “servidores”, sino que todos ellos se comportan como clientes y como servidores a la vez. Así, en las redes P2P se establece una conexión directa entre usuarios, donde cualquier nodo puede transmitir información al mismo tiempo que la recibe. Lo que se comparte en estas redes es información que está almacenada en los discos rígidos de las computadoras personales de cada usuario en línea.
La historia de las Redes P2P se hizo popular y llegó a las primeras planas de los diarios con el famoso caso Napster, la primera aplicación P2P, que llegó a tener más de 13 millones de usuarios conectados en todo el planeta. Napster ya es historia: los juicios de las discográficas lo llevaron a la ruina, y hoy se ha convertido en un servicio pago al que los usuarios le dan la espalda. Después de Napster aparecieron varias otras redes que, a diferencia de ésta, se caracterizan por su arquitectura descentralizada, lo que las hace mucho más difíciles de “apagar”.
La controversia legal más fuerte en relación a estas redes es el hecho de que muchos de sus usuarios las utilizan para distribuir material sujeto a copyright, sin debida autorización de los titulares de los derechos. Según esta visión, las redes P2P son herramientas de violación masiva de copyright, y deben ser eliminadas. En medio de la histeria mediática, sin embargo, no debemos olvidar que las redes P2P tienen muchos usos que no afectan el copyright en absoluto: se usan para distribuir software libre, música libre, obras de los propios usuarios o del dominio público, etc.
Quienes recuerdan la historia del copyright, además, llaman la atención sobre el hecho de que aún cuando las redes P2P son usadas para distribuir obras bajo copyright, el intercambio no genera para ninguna de las partes un resultado de lucro económico. El copyright originalmente sólo era aplicable a actividades comerciales, de las que las redes P2P no son parte. Sólo recientemente y, a los ojos de muchos estudiosos del tema, indebidamente, aparecieron interpretaciones del copyright según las cuales la reproducción no comercial también está restringida. Así, la pregunta acerca de si existe un verdadero derecho a impedir que las personas compartan lo que está en sus discos rígidos con pares que hacen lo mismo sigue abierta.
Fuente: http://www.vialibre.org.ar/
"En las redes P2P se establece una conexión directa entre usuarios, donde cualquier nodo puede transmitir información al mismo tiempo que la recibe."
Una red P2P se forma a partir de la interconexión entre pares (peers). En otras palabras, en una red P2P los participantes no asumen roles separados como “clientes” y “servidores”, sino que todos ellos se comportan como clientes y como servidores a la vez. Así, en las redes P2P se establece una conexión directa entre usuarios, donde cualquier nodo puede transmitir información al mismo tiempo que la recibe. Lo que se comparte en estas redes es información que está almacenada en los discos rígidos de las computadoras personales de cada usuario en línea.
La historia de las Redes P2P se hizo popular y llegó a las primeras planas de los diarios con el famoso caso Napster, la primera aplicación P2P, que llegó a tener más de 13 millones de usuarios conectados en todo el planeta. Napster ya es historia: los juicios de las discográficas lo llevaron a la ruina, y hoy se ha convertido en un servicio pago al que los usuarios le dan la espalda. Después de Napster aparecieron varias otras redes que, a diferencia de ésta, se caracterizan por su arquitectura descentralizada, lo que las hace mucho más difíciles de “apagar”.
La controversia legal más fuerte en relación a estas redes es el hecho de que muchos de sus usuarios las utilizan para distribuir material sujeto a copyright, sin debida autorización de los titulares de los derechos. Según esta visión, las redes P2P son herramientas de violación masiva de copyright, y deben ser eliminadas. En medio de la histeria mediática, sin embargo, no debemos olvidar que las redes P2P tienen muchos usos que no afectan el copyright en absoluto: se usan para distribuir software libre, música libre, obras de los propios usuarios o del dominio público, etc.
Quienes recuerdan la historia del copyright, además, llaman la atención sobre el hecho de que aún cuando las redes P2P son usadas para distribuir obras bajo copyright, el intercambio no genera para ninguna de las partes un resultado de lucro económico. El copyright originalmente sólo era aplicable a actividades comerciales, de las que las redes P2P no son parte. Sólo recientemente y, a los ojos de muchos estudiosos del tema, indebidamente, aparecieron interpretaciones del copyright según las cuales la reproducción no comercial también está restringida. Así, la pregunta acerca de si existe un verdadero derecho a impedir que las personas compartan lo que está en sus discos rígidos con pares que hacen lo mismo sigue abierta.
Fuente: http://www.vialibre.org.ar/
MODELOS CLIENTE/SERVIDOR
Una de las clasificaciones mejor conocidas de las arquitecturas Cliente/Servidor se basa en la idea de planos (tier), la cual es una variación sobre la división o clasificación por tamaño de componentes. Esto se debe a que se trata de definir el modo en que las prestaciones funcionales de la aplicación serán asignadas, y en qué proporción, tanto al cliente como al servidor. Dichas prestaciones se deben agrupar entre los tres componentes clásicos para Cliente/Servidor: interfaz de usuario, lógica de negocios y los datos compartidos, cada uno de los cuales corresponde a un plano. Ni que decir tiene que la mala elección de uno u otro modelo puede llegar a tener consecuencias fatales.
Dentro de esta categoría tenemos las aplicaciones en dos planos (two-tier), tres planos (three-tier) y multi-planos (multi-tier). Dado que este término ha sido sobrecargado de significados por cuanto se lo utiliza indistintamente para referirse tanto a aspectos lógicos (Software) como físicos (Hardware), aquí se esquematizan ambas acepciones.
A NIVEL DE SOFTWARE
Este enfoque o clasificación es el más generalizado y el que más se ajusta a los enfoques modernos, dado que se fundamenta en los componentes lógicos de la estructura Cliente/Servidor y en la madurez y popularidad de la computación distribuida. Por ejemplo, esto permite hablar de servidores de aplicación distribuidos a lo largo de una red, y no tiene mucho sentido identificar a un equipo de hardware como servidor, si no más bien entenderlo como una plataforma física sobre la cual pueden operar uno o más servidores de aplicaciones.
Este enfoque o clasificación es el más generalizado y el que más se ajusta a los enfoques modernos, dado que se fundamenta en los componentes lógicos de la estructura Cliente/Servidor y en la madurez y popularidad de la computación distribuida. Por ejemplo, esto permite hablar de servidores de aplicación distribuidos a lo largo de una red, y no tiene mucho sentido identificar a un equipo de hardware como servidor, si no más bien entenderlo como una plataforma física sobre la cual pueden operar uno o más servidores de aplicaciones.
MODELO CLIENTE/SERVIDOR 2 CAPAS
Esta estructura se caracteriza por la conexión directa entre el proceso cliente y un administrador de bases de datos. Dependiendo de donde se localice el grupo de tareas correspondientes a la lógica de negocios se pueden tener a su vez dos tipos distintos dentro de esta misma categoría:
IMPLEMENTADO CON SQL REMOTO
En este esquema el cliente envía mensajes con solicitudes SQL al servidor de bases de datos y el resultado de cada instrucción SQL es devuelto por la red, no importando si son uno, diez, cien o mil registros. Es el mismo cliente quien debe procesar todos los registros que le fueron devueltos por el servidor de base de datos, según el requerimiento que él mismo hizo. Esto hace que este tipo de estructura se adecue a los requerimientos de aplicaciones orientadas a los sistemas de apoyo y gestión, pero resultan inadecuados para los sistemas críticos en que se requieran bajos tiempos de respuesta.
Esta estructura se caracteriza por la conexión directa entre el proceso cliente y un administrador de bases de datos. Dependiendo de donde se localice el grupo de tareas correspondientes a la lógica de negocios se pueden tener a su vez dos tipos distintos dentro de esta misma categoría:
IMPLEMENTADO CON SQL REMOTO
En este esquema el cliente envía mensajes con solicitudes SQL al servidor de bases de datos y el resultado de cada instrucción SQL es devuelto por la red, no importando si son uno, diez, cien o mil registros. Es el mismo cliente quien debe procesar todos los registros que le fueron devueltos por el servidor de base de datos, según el requerimiento que él mismo hizo. Esto hace que este tipo de estructura se adecue a los requerimientos de aplicaciones orientadas a los sistemas de apoyo y gestión, pero resultan inadecuados para los sistemas críticos en que se requieran bajos tiempos de respuesta.
Ventajas:
Presenta una estructura de desarrollo bastante simple ya que el programador maneja un único ambiente de desarrollo (es más simple respecto al Cliente/Servidor en tres planos, puesto que reduce una capa de programación, como se verá más adelante).
Inconvenientes:
La gran cantidad de información que viaja al cliente congestiona demasiado el tráfico de red, lo que se traduce en bajo rendimiento.
Por su bajo rendimiento esta estructura tiene un bajo espectro de aplicación, limitándose a la construcción de sistemas no críticos.
Presenta una estructura de desarrollo bastante simple ya que el programador maneja un único ambiente de desarrollo (es más simple respecto al Cliente/Servidor en tres planos, puesto que reduce una capa de programación, como se verá más adelante).
Inconvenientes:
La gran cantidad de información que viaja al cliente congestiona demasiado el tráfico de red, lo que se traduce en bajo rendimiento.
Por su bajo rendimiento esta estructura tiene un bajo espectro de aplicación, limitándose a la construcción de sistemas no críticos.
IMPLEMENTADO CON PROCEDIMIENTOS ALMACENADOS
En este esquema el cliente envía llamadas a funciones que residen en la base de datos, y es ésta quien resuelve y procesa la totalidad de las instrucciones SQL agrupadas en la mencionada función.
Ventajas: Presenta las mismas ventajas de una arquitectura dos planos con procedimientos almacenados, pero mejora considerablemente el rendimiento sobre ésta, dado que reduce el tráfico por la red al procesar los datos en la misma base de datos, haciendo viajar sólo el resultado final de un conjunto de instrucciones SQL.
Inconvenientes: Si bien la complejidad de desarrollo se ve disminuida, se pierde flexibilidad y escalabilidad en las soluciones implantadas. Obliga a basar el peso de la aplicación en SQL extendido, propios del proveedor de la base de datos que se elija. Debiera considerarse que sí bien los procedimientos almacenados (stored procedures), los desencadenantes (triggers) y las reglas (constraint) son útiles, en rigor son ajenos al estándar de SQL
En este esquema el cliente envía llamadas a funciones que residen en la base de datos, y es ésta quien resuelve y procesa la totalidad de las instrucciones SQL agrupadas en la mencionada función.
Ventajas: Presenta las mismas ventajas de una arquitectura dos planos con procedimientos almacenados, pero mejora considerablemente el rendimiento sobre ésta, dado que reduce el tráfico por la red al procesar los datos en la misma base de datos, haciendo viajar sólo el resultado final de un conjunto de instrucciones SQL.
Inconvenientes: Si bien la complejidad de desarrollo se ve disminuida, se pierde flexibilidad y escalabilidad en las soluciones implantadas. Obliga a basar el peso de la aplicación en SQL extendido, propios del proveedor de la base de datos que se elija. Debiera considerarse que sí bien los procedimientos almacenados (stored procedures), los desencadenantes (triggers) y las reglas (constraint) son útiles, en rigor son ajenos al estándar de SQL
MODELO CLIENTE/SERVIDOR 3 CAPAS
Esta estructura se caracteriza por elaborar la aplicación en base a dos capas principales de software, más la capa correspondiente al servidor de base de datos. Al igual que en la arquitectura dos capas, y según las decisiones de diseño que se tomen, se puede balancear la carga de trabajo entre el proceso cliente y el nuevo proceso correspondiente al servidor de aplicación.
En este esquema el cliente envía mensajes directamente al servidor de aplicación el cual debe administrar y responder todas las solicitudes. Es el servidor, dependiendo del tipo de solicitud, quien accede y se conecta con la base de datos.
Ventajas:
Reduce el tráfico de información en la red por lo que mejora el rendimiento de los sistemas (especialmente respecto a la estructura en dos planos).
Brinda una mayor flexibilidad de desarrollo y de elección de plataformas sobre la cual montar las aplicaciones. Provee escalabilidad horizontal y vertical.
Se mantiene la independencia entre el código de la aplicación (reglas y conocimiento del negocio) y los datos, mejorando la portabilidad de las aplicaciones.
Los lenguajes sobre los cuales se desarrollan las aplicaciones son estándares lo que hace más exportables las aplicaciones entre plataformas.
Dado que mejora el rendimiento al optimizar el flujo de información entre componentes, permite construir sistemas críticos de alta fiabilidad.
El mismo hecho de localizar las reglas del negocio en su propio ambiente, en vez de distribuirlos en la capa de interfaz de usuario, permite reducir el impacto de hacer mantenimiento, cambios urgentes de última hora o mejoras al sistema.
Disminuye el número de usuarios (licencias) conectados a la base de datos.
Inconvenientes:
Dependiendo de la elección de los lenguajes de desarrollo, puede presentar mayor complejidad en comparación con Cliente/Servidor dos planos.
Existen pocos proveedores de herramientas integradas de desarrollo con relación al modelo Cliente/Servidor dos planos, y normalmente son de alto costo.
Esta estructura se caracteriza por elaborar la aplicación en base a dos capas principales de software, más la capa correspondiente al servidor de base de datos. Al igual que en la arquitectura dos capas, y según las decisiones de diseño que se tomen, se puede balancear la carga de trabajo entre el proceso cliente y el nuevo proceso correspondiente al servidor de aplicación.
En este esquema el cliente envía mensajes directamente al servidor de aplicación el cual debe administrar y responder todas las solicitudes. Es el servidor, dependiendo del tipo de solicitud, quien accede y se conecta con la base de datos.
Ventajas:
Reduce el tráfico de información en la red por lo que mejora el rendimiento de los sistemas (especialmente respecto a la estructura en dos planos).
Brinda una mayor flexibilidad de desarrollo y de elección de plataformas sobre la cual montar las aplicaciones. Provee escalabilidad horizontal y vertical.
Se mantiene la independencia entre el código de la aplicación (reglas y conocimiento del negocio) y los datos, mejorando la portabilidad de las aplicaciones.
Los lenguajes sobre los cuales se desarrollan las aplicaciones son estándares lo que hace más exportables las aplicaciones entre plataformas.
Dado que mejora el rendimiento al optimizar el flujo de información entre componentes, permite construir sistemas críticos de alta fiabilidad.
El mismo hecho de localizar las reglas del negocio en su propio ambiente, en vez de distribuirlos en la capa de interfaz de usuario, permite reducir el impacto de hacer mantenimiento, cambios urgentes de última hora o mejoras al sistema.
Disminuye el número de usuarios (licencias) conectados a la base de datos.
Inconvenientes:
Dependiendo de la elección de los lenguajes de desarrollo, puede presentar mayor complejidad en comparación con Cliente/Servidor dos planos.
Existen pocos proveedores de herramientas integradas de desarrollo con relación al modelo Cliente/Servidor dos planos, y normalmente son de alto costo.
A NIVEL DE HARDWARE
Esta clasificación del modelo Cliente/Servidor se basa igualmente en la distribución de los procesos y elementos entre sus componentes, pero centrándose en la parte física del mismo, en el que la administración de la interfaz gráfica se asocia a los clientes PC y la seguridad e integridad de los datos quedan asociados a ambientes mainframe o por lo menos a servidores locales y/o centrales.
Esta clasificación del modelo Cliente/Servidor se basa igualmente en la distribución de los procesos y elementos entre sus componentes, pero centrándose en la parte física del mismo, en el que la administración de la interfaz gráfica se asocia a los clientes PC y la seguridad e integridad de los datos quedan asociados a ambientes mainframe o por lo menos a servidores locales y/o centrales.
MODELO CLIENTE / SERVIDOR 2 CAPAS
Los clientes son conectados vía LAN a un servidor de aplicaciones local, el cual, dependiendo de la aplicación puede dar acceso a los datos administrados por él.
MODELO CLIENTE / SERVIDOR 3 CAPAS
Los clientes son conectados vía LAN a un servidor de aplicaciones local, el cual a su vez se comunica con un servidor central de bases de datos. El servidor local tiene un comportamiento dual, dado que actúa como cliente o servidor en función de la dirección de la comunicación.
Los clientes son conectados vía LAN a un servidor de aplicaciones local, el cual, dependiendo de la aplicación puede dar acceso a los datos administrados por él.
MODELO CLIENTE / SERVIDOR 3 CAPAS
Los clientes son conectados vía LAN a un servidor de aplicaciones local, el cual a su vez se comunica con un servidor central de bases de datos. El servidor local tiene un comportamiento dual, dado que actúa como cliente o servidor en función de la dirección de la comunicación.
MODELOS CLIENTE / SERVIDOR SEGÚN EL REPARTO DE FUNCIONES ENTRE CLIENTE Y SERVIDOR.
Separación de funciones.
Las distintas arquitecturas cliente/servidor presentan variaciones acerca de cómo son distribuidas las diferentes funciones de las aplicaciones de sistemas entre el cliente y el servidor, sobre la base de los conceptos de los tres componentes generales de cualquier SI:
La lógica de acceso a datos. Funciones que gestionan todas las interacciones entre el SW y los almacenes de datos (archivos, bases de datos, etc.) incluyendo recuperación/consulta, actualización, seguridad y control de concurrencia.
La lógica de presentación. Funciones que gestionan la interfaz entre los usuarios del sistema y el SW, incluyendo la visualización e impresión de formas y reportes, y la posibilidad de validar entradas del sistema.
La lógica de negocio o lógica de la aplicación. Funciones que transforman entradas en salidas, incluyendo desde simples sumas hasta complejos modelos matemáticos, financieros, científicos, de ingeniería, etc.
Según cómo se distribuyan las funciones correspondientes a estas tres lógicas o funciones de un sistema entre cliente, middleware y servidor (los principales componentes de un sistema con arquitectura distribuída) nos podemos encontrar con los siguientes tipos de arquitectura cliente / servidor (conforme a la célebre clasificación hecha por el Gartner Group):
Presentación Distribuida.
Presentación remota.
Acceso a datos remoto.
Lógica o procesamiento distribuídas.
Bases de datos distribuídas.
La importancia de esta clasificación radica en que permite jugar con el ancho de banda de la red y con la capacidad de proceso de los componentes hardware del sistema para repartir entre ellos la carga de proceso de las lógicas de la aplicación. Seguidamente entraremos en más detalle sobre estos tipos de arquitectura.
Presentación distribuída.
El cliente asume parte de las funciones de presentación de la aplicación, ya que siguen existiendo programas en el servidor dedicados a esta tarea. El resto de funciones de la aplicación (negocio, acceso a datos) residen en el servidor.
Esta arquitectura se utiliza para construir emuladores de terminal, aplicaciones de control remoto, front ends gráficos de aplicaciones que residen en un host, etc. Algunos ejemplos de productos que siguen esta filosofía son VLC, Microsoft Terminal Server, Cytrix Metaframe, emulador de host para sistemas operativos modernos como Windows, etc.
La gran ventaja de esta arquitectura es que permite revitalizar sistemas antiguos. Así, las aplicaciones antiguas que funcionaban en entornos host pueden ser empleadas desde modernas estaciones de trabajo Windows o Microsoft (que solamente hacen la función de términal del host incrustada en un entorno de trabajo de escritorio moderno).
El principal problema es que no se elimina la dependencia del host, no siendo posible la aplicación de los conceptos de downsizing o rightsizing.
Presentación remota.
Toda la lógica de negocio y acceso a datos se ejecuta en el servidor, que en esta ocasión no realiza ninguna función relacionada con la presentación. Todas las funciones de presentación son ejecutadas en el cliente. Un ejemplo de este tipo de aplicaciones son las aplicaciones web, las de los terminales de cajeros automáticos, etc.
La principal ventaja es que la interfaz de usuario se adapta bien a las capacidades del entorno cliente (en la presentación distribuída el servidor tenía que ejecutar funciones dentro de un entorno que podría no ser el más apropiado para el cliente). La principal desventaja es que toda la información necesaria para la presentación tiene que circular por la red desde el servidor al cliente.
Lógica o proceso distribuído.
La lógica de los procesos se divide entre los distintos componentes del cliente y del servidor. El diseñador de la aplicación debe definir los servicios y las interfaces del sistema de información de forma que los papeles de cliente y servidor sean intercambiables, excepto en el control de los datos que es responsabilidad exclusiva del servidor. En este tipo de situaciones se dice que hay un proceso distribuido o cooperativo.
La principal ventaja de esta arquitectura es que cada uno de los nodos/servidores puede especializarse en un área determinada, de forma que cada proceso se ejecutará en el nodo más apropiado. Además, se pueden reutilizar los sistemas ya existentes (es una especie de antesala delconcepto de SOA).
En contrapartida, este tipo de sistemas son más dificiles de diseñar, de mantener y de probar.
Acceso a datos remoto.
El cliente realiza tanto las funciones de presentación como los procesos. Por su parte, el servidor almacena y gestiona los datos que permanecen en una base de datos centralizada. En esta situación se dice que hay una gestión de datos remota.
La principal ventaja de esta arquitectura radica en su sencillez de uso, y su proliferación al ser adaptada por lenguajes de cuarta generación (como Oracle Forms). La desventaja es la latencia de red introducida. Al descargarse toda la lógica de proceso en los aplicativos clientes, estos necesitan descargar los datos necesarios (entradas al proceso) que circulan por la red.
Bases de datos distribuídas.
Este modelo es similar al de Acceso a Datos Remoto, pero además el gestor de base de datos divide sus componentes entre el cliente y el servidor. Las interfaces entre ambos están dentro de las funciones del gestor de datos y, por lo tanto, no tienen impacto en el desarrollo de las aplicaciones. En este nivel se da lo que se conoce como bases de datos distribuidas.
La principal ventaja de este modelo es que facilita el acceso a los datos desde entornos heterogéneos. Los componentes de acceso a datos ubicados en el cliente permiten independizar la base de datos del entorno en el que corren las aplicaciones cliente. Además, permite implementar la "transparencia de ubicación". Este sistema presenta dos importantes inconvenientes:
Las bases de datos distribuídas son más difíciles de implementar, y son dependientes del gestor de base de datos (siempre que no existan acuerdos y estándares)
La integridad de los datos puede verse comprometida.
Separación de funciones.
Las distintas arquitecturas cliente/servidor presentan variaciones acerca de cómo son distribuidas las diferentes funciones de las aplicaciones de sistemas entre el cliente y el servidor, sobre la base de los conceptos de los tres componentes generales de cualquier SI:
La lógica de acceso a datos. Funciones que gestionan todas las interacciones entre el SW y los almacenes de datos (archivos, bases de datos, etc.) incluyendo recuperación/consulta, actualización, seguridad y control de concurrencia.
La lógica de presentación. Funciones que gestionan la interfaz entre los usuarios del sistema y el SW, incluyendo la visualización e impresión de formas y reportes, y la posibilidad de validar entradas del sistema.
La lógica de negocio o lógica de la aplicación. Funciones que transforman entradas en salidas, incluyendo desde simples sumas hasta complejos modelos matemáticos, financieros, científicos, de ingeniería, etc.
Según cómo se distribuyan las funciones correspondientes a estas tres lógicas o funciones de un sistema entre cliente, middleware y servidor (los principales componentes de un sistema con arquitectura distribuída) nos podemos encontrar con los siguientes tipos de arquitectura cliente / servidor (conforme a la célebre clasificación hecha por el Gartner Group):
Presentación Distribuida.
Presentación remota.
Acceso a datos remoto.
Lógica o procesamiento distribuídas.
Bases de datos distribuídas.
La importancia de esta clasificación radica en que permite jugar con el ancho de banda de la red y con la capacidad de proceso de los componentes hardware del sistema para repartir entre ellos la carga de proceso de las lógicas de la aplicación. Seguidamente entraremos en más detalle sobre estos tipos de arquitectura.
Presentación distribuída.
El cliente asume parte de las funciones de presentación de la aplicación, ya que siguen existiendo programas en el servidor dedicados a esta tarea. El resto de funciones de la aplicación (negocio, acceso a datos) residen en el servidor.
Esta arquitectura se utiliza para construir emuladores de terminal, aplicaciones de control remoto, front ends gráficos de aplicaciones que residen en un host, etc. Algunos ejemplos de productos que siguen esta filosofía son VLC, Microsoft Terminal Server, Cytrix Metaframe, emulador de host para sistemas operativos modernos como Windows, etc.
La gran ventaja de esta arquitectura es que permite revitalizar sistemas antiguos. Así, las aplicaciones antiguas que funcionaban en entornos host pueden ser empleadas desde modernas estaciones de trabajo Windows o Microsoft (que solamente hacen la función de términal del host incrustada en un entorno de trabajo de escritorio moderno).
El principal problema es que no se elimina la dependencia del host, no siendo posible la aplicación de los conceptos de downsizing o rightsizing.
Presentación remota.
Toda la lógica de negocio y acceso a datos se ejecuta en el servidor, que en esta ocasión no realiza ninguna función relacionada con la presentación. Todas las funciones de presentación son ejecutadas en el cliente. Un ejemplo de este tipo de aplicaciones son las aplicaciones web, las de los terminales de cajeros automáticos, etc.
La principal ventaja es que la interfaz de usuario se adapta bien a las capacidades del entorno cliente (en la presentación distribuída el servidor tenía que ejecutar funciones dentro de un entorno que podría no ser el más apropiado para el cliente). La principal desventaja es que toda la información necesaria para la presentación tiene que circular por la red desde el servidor al cliente.
Lógica o proceso distribuído.
La lógica de los procesos se divide entre los distintos componentes del cliente y del servidor. El diseñador de la aplicación debe definir los servicios y las interfaces del sistema de información de forma que los papeles de cliente y servidor sean intercambiables, excepto en el control de los datos que es responsabilidad exclusiva del servidor. En este tipo de situaciones se dice que hay un proceso distribuido o cooperativo.
La principal ventaja de esta arquitectura es que cada uno de los nodos/servidores puede especializarse en un área determinada, de forma que cada proceso se ejecutará en el nodo más apropiado. Además, se pueden reutilizar los sistemas ya existentes (es una especie de antesala delconcepto de SOA).
En contrapartida, este tipo de sistemas son más dificiles de diseñar, de mantener y de probar.
Acceso a datos remoto.
El cliente realiza tanto las funciones de presentación como los procesos. Por su parte, el servidor almacena y gestiona los datos que permanecen en una base de datos centralizada. En esta situación se dice que hay una gestión de datos remota.
La principal ventaja de esta arquitectura radica en su sencillez de uso, y su proliferación al ser adaptada por lenguajes de cuarta generación (como Oracle Forms). La desventaja es la latencia de red introducida. Al descargarse toda la lógica de proceso en los aplicativos clientes, estos necesitan descargar los datos necesarios (entradas al proceso) que circulan por la red.
Bases de datos distribuídas.
Este modelo es similar al de Acceso a Datos Remoto, pero además el gestor de base de datos divide sus componentes entre el cliente y el servidor. Las interfaces entre ambos están dentro de las funciones del gestor de datos y, por lo tanto, no tienen impacto en el desarrollo de las aplicaciones. En este nivel se da lo que se conoce como bases de datos distribuidas.
La principal ventaja de este modelo es que facilita el acceso a los datos desde entornos heterogéneos. Los componentes de acceso a datos ubicados en el cliente permiten independizar la base de datos del entorno en el que corren las aplicaciones cliente. Además, permite implementar la "transparencia de ubicación". Este sistema presenta dos importantes inconvenientes:
Las bases de datos distribuídas son más difíciles de implementar, y son dependientes del gestor de base de datos (siempre que no existan acuerdos y estándares)
La integridad de los datos puede verse comprometida.
Arquitecturas de redes
Red en árbol: los nodos están colocados en forma de árbol. No tiene un nodo central. La topología en árbol puede verse como una combinación de varias topologías en estrella.

Red en malla: cada nodo está conectado a todos los nodos. De esta manera es posible llevar los mensajes de un nodo a otro por diferentes caminos. Si la red de malla está completamente conectada, puede existir absolutamente ninguna interrupción en las comunicaciones. Cada servidor tiene sus propias conexiones con todos los demás servidores.

Red en anillo: Topología de red en la que cada estación está conectada a la siguiente y la última está conectada a la primera. Cada estación tiene un receptor y un transmisor que hace la función de repetidor, pasando la señal a la siguiente estación.

Red en estrella: las estaciones están conectadas directamente a un punto central y todas las comunicaciones se han de hacer necesariamente a través de este. Los dispositivos no están directamente conectados entre sí, además de que no se permite tanto tráfico de información. Dado su transmisión, una red en estrella activa tiene un nodo central activo que normalmente tiene los medios para prevenir problemas relacionados con el eco.

Red en bus: se caracteriza por tener un único canal de comunicaciones (denominado bus, troncal o backbone) al cual se conectan los diferentes dispositivos. De esta forma todos los dispositivos comparten el mismo canal para comunicarse entre sí.


{kind=link}
Red en malla: cada nodo está conectado a todos los nodos. De esta manera es posible llevar los mensajes de un nodo a otro por diferentes caminos. Si la red de malla está completamente conectada, puede existir absolutamente ninguna interrupción en las comunicaciones. Cada servidor tiene sus propias conexiones con todos los demás servidores.

Red en anillo: Topología de red en la que cada estación está conectada a la siguiente y la última está conectada a la primera. Cada estación tiene un receptor y un transmisor que hace la función de repetidor, pasando la señal a la siguiente estación.

Red en estrella: las estaciones están conectadas directamente a un punto central y todas las comunicaciones se han de hacer necesariamente a través de este. Los dispositivos no están directamente conectados entre sí, además de que no se permite tanto tráfico de información. Dado su transmisión, una red en estrella activa tiene un nodo central activo que normalmente tiene los medios para prevenir problemas relacionados con el eco.

Red en bus: se caracteriza por tener un único canal de comunicaciones (denominado bus, troncal o backbone) al cual se conectan los diferentes dispositivos. De esta forma todos los dispositivos comparten el mismo canal para comunicarse entre sí.

Tipos de redes de información
LAN (Local Area Network, redes de área local):
Son privadas y se usan para conectar computadores personales y estaciones de trabajo de una oficina, fábricas, otro objetivo intercambian información. Las LAN están restringidas en tamaño porque el tiempo de transmisión esta limitado, opera a una velocidad de 10 a 100 mega bites por segundo. Suelen emplear tecnología de difusión mediante un cable sencillo (coaxial o UTP) al que están conectadas todas las máquinas.
WAN (Wide Area Network, redes de área extensa):
Es extensa geográficamente en un país o continente. Sus velocidades son menores que en las LAN aunque son capaces de transportar una mayor cantidad de datos. Una red de área extensa WAN es un sistema de interconexión de equipos informáticos geográficamente dispersos, incluso en continentes distintos. Las líneas utilizadas para realizar esta interconexión suelen ser parte de las redes públicas de transmisión de datos.
Las redes LAN están conectadas a éstas por ejemplo con la conexión internet.
MAN (Metropolitan Area Network, redes de área metropolitana):
comprenden una ubicación geográfica determinada "ciudad, municipio", y su distancia de cobertura es mayor de 4 Kmts.
REDES PUNTO A PUNTO :Conexiones directas entre terminales y computadoras, tienen alta velocidad de transmisión, seguras, inconveniente costo, proporciona mas flexibilidad que una red con servidor ya que permite que cualquier computadora comparta sus recursos.
REDES DE DIFUCION:Poseen un solo canal de comunicaciones compartido por todas las maquinas de la red, cuando el mensaje es enviado se recibe por todas las demás verifican el campo de dirección si es para ella se procesa de lo contrario se ignora. Pero este tipo de red permite mediante un código la posibilidad de dirigir un paquete a todos los destinos permitiendo que todas las maquinas lo reciban y procesen.
REDES CONMUTADAS: Los datos provienen de dispositivos finales que desean comunicarse conmutando de nodo a nodo objetivo facilitar la comunicación.
PAN(Personal Area Network, Red de Área Personal):
Una red personal del área (PAN) es una red de ordenadores usada para la comunicación entre los dispositivos de la computadora (teléfonos incluyendo las ayudantes digitales personales) cerca de una persona. Están conformadas por no más de 8 equipos, por ejemplo: café Internet.
Información de Monografias.com
Son privadas y se usan para conectar computadores personales y estaciones de trabajo de una oficina, fábricas, otro objetivo intercambian información. Las LAN están restringidas en tamaño porque el tiempo de transmisión esta limitado, opera a una velocidad de 10 a 100 mega bites por segundo. Suelen emplear tecnología de difusión mediante un cable sencillo (coaxial o UTP) al que están conectadas todas las máquinas.
WAN (Wide Area Network, redes de área extensa):
Es extensa geográficamente en un país o continente. Sus velocidades son menores que en las LAN aunque son capaces de transportar una mayor cantidad de datos. Una red de área extensa WAN es un sistema de interconexión de equipos informáticos geográficamente dispersos, incluso en continentes distintos. Las líneas utilizadas para realizar esta interconexión suelen ser parte de las redes públicas de transmisión de datos.
Las redes LAN están conectadas a éstas por ejemplo con la conexión internet.
MAN (Metropolitan Area Network, redes de área metropolitana):
comprenden una ubicación geográfica determinada "ciudad, municipio", y su distancia de cobertura es mayor de 4 Kmts.
REDES PUNTO A PUNTO :Conexiones directas entre terminales y computadoras, tienen alta velocidad de transmisión, seguras, inconveniente costo, proporciona mas flexibilidad que una red con servidor ya que permite que cualquier computadora comparta sus recursos.
REDES DE DIFUCION:Poseen un solo canal de comunicaciones compartido por todas las maquinas de la red, cuando el mensaje es enviado se recibe por todas las demás verifican el campo de dirección si es para ella se procesa de lo contrario se ignora. Pero este tipo de red permite mediante un código la posibilidad de dirigir un paquete a todos los destinos permitiendo que todas las maquinas lo reciban y procesen.
REDES CONMUTADAS: Los datos provienen de dispositivos finales que desean comunicarse conmutando de nodo a nodo objetivo facilitar la comunicación.
PAN(Personal Area Network, Red de Área Personal):
Una red personal del área (PAN) es una red de ordenadores usada para la comunicación entre los dispositivos de la computadora (teléfonos incluyendo las ayudantes digitales personales) cerca de una persona. Están conformadas por no más de 8 equipos, por ejemplo: café Internet.
Información de Monografias.com
RED SATELITAL
Una red satelital consiste de un transponder (dispositivo receptor-transmisor), una estación basada en tierra que controlar su funcionamiento y una red de usuario, de las estaciones terrestres, que proporciona las facilidades para transmisión y recepción del tráfico de comunicaciones, a través del sistema de satélite.
CARACTERÍSTICAS DE LAS REDES SATELITALES
En el caso de radiodifusión directa de televisión vía satélite el servicio que se da es de tipo unidireccional por lo que normalmente se requiere una estación transmisora única, que emite los programas hacia el satélite, y varias estaciones terrenas de recepción solamente, que toman las señales provenientes del satélite. Existen otros tipos de servicios que son bidireccionales donde las estaciones terrenas son de transmisión y de recepción.
Uno de los requisitos más importantes del sistema es conseguir que las estaciones sean lo más económicas posibles para que puedan ser accesibles a un gran numero de usuarios, lo que se consigue utilizando antenas de diámetro chico y transmisores de baja potencia. Sin embargo hay que destacar que es la economía de escala (en aquellas aplicaciones que lo permiten) el factor determinante para la reducción de los costos.
Fuente: blogcindario.com
CARACTERÍSTICAS DE LAS REDES SATELITALES
- Las transmisiones son realizadas a altas velocidades en Giga Hertz.
- Son muy costosas, por lo que su uso se ve limitado a grandes empresas y países
- Rompen las distancias y el tiempo.
En el caso de radiodifusión directa de televisión vía satélite el servicio que se da es de tipo unidireccional por lo que normalmente se requiere una estación transmisora única, que emite los programas hacia el satélite, y varias estaciones terrenas de recepción solamente, que toman las señales provenientes del satélite. Existen otros tipos de servicios que son bidireccionales donde las estaciones terrenas son de transmisión y de recepción.
Uno de los requisitos más importantes del sistema es conseguir que las estaciones sean lo más económicas posibles para que puedan ser accesibles a un gran numero de usuarios, lo que se consigue utilizando antenas de diámetro chico y transmisores de baja potencia. Sin embargo hay que destacar que es la economía de escala (en aquellas aplicaciones que lo permiten) el factor determinante para la reducción de los costos.
Fuente: blogcindario.com
RED TELEFÓNICA
La red telefónica es la de mayor cobertura geográfica, la que mayor número de usuarios tiene, y ocasionalmente se ha afirmado que es "el sistema más complejo del que dispone la humanidad". Permite establecer una llamada entre dos usuarios en cualquier parte del planeta de manera distribuida, automática, prácticamente instantánea. Este es el ejemplo más importante de una red con conmutación de circuitos.
Existen 2 tipos de redes telefónicas, las redes publicas que a su vez se dividen en red publica móvil y red publica fija. Y también existen las redes telefónicas privadas que están básicamente formadas por un conmutador.
Las redes telefónicas publicas fijas, están formados por diferentes tipos de centrales, que se utilizan según el tipo de llamada realizada por el usuarios. Éstas son:
Asimismo existen nodos (centrales) que permiten enrutar una llamada hacia otra localidad, ya sea dentro o fuera del país. Este tipo de centrales se denominan centrales automáticas de larga distancia. El inicio de una llamada de larga distancia es identificado por la central por medio del primer dígito (en México, un "9"), y el segundo dígito le indica el tipo de enlace (nacional o internacional; en este último caso, le indica también el país de que se trata). A pesar de que el acceso a las centrales de larga distancia se realiza en cada país por medio de un código propio, éste señala, sin lugar a dudas, cuál es el destino final de la llamada. El código de un país es independiente del que origina la llamada.
Cada una de estas centrales telefónicas, están divididas a su vez en 2 partes principales:
Existen 2 tipos de redes telefónicas, las redes publicas que a su vez se dividen en red publica móvil y red publica fija. Y también existen las redes telefónicas privadas que están básicamente formadas por un conmutador.
Las redes telefónicas publicas fijas, están formados por diferentes tipos de centrales, que se utilizan según el tipo de llamada realizada por el usuarios. Éstas son:
- CCA – Central con Capacidad de Usuario
- CCE – Central con Capacidad de Enlace
- CTU – Central de Transito Urbano
- CTI – Central de Transito Internacional
- CI – Central Internacional
- CM – Central Mundial
Asimismo existen nodos (centrales) que permiten enrutar una llamada hacia otra localidad, ya sea dentro o fuera del país. Este tipo de centrales se denominan centrales automáticas de larga distancia. El inicio de una llamada de larga distancia es identificado por la central por medio del primer dígito (en México, un "9"), y el segundo dígito le indica el tipo de enlace (nacional o internacional; en este último caso, le indica también el país de que se trata). A pesar de que el acceso a las centrales de larga distancia se realiza en cada país por medio de un código propio, éste señala, sin lugar a dudas, cuál es el destino final de la llamada. El código de un país es independiente del que origina la llamada.
Cada una de estas centrales telefónicas, están divididas a su vez en 2 partes principales:
- La parte de control, se lleva a cabo por diferentes microprocesadores, los cuales se encargan de enrutar, direccionar, limitar y dar diferentes tipos de servicios a los usuarios.
- La parte de conmutación se encarga de las interconexiones necesarias en los equipos para poder realizar las llamadas.
Fuente: monografias.com
martes, 15 de noviembre de 2011
RED DE DATOS
Se conoce como red de datos a la infraestructura cuyo diseño posibilita la transmisión de información a través del intercambio de datos. Cada una de estas redes ha sido diseñada específicamente para satisfacer sus objetivos, con una arquitectura determinada para facilitar el intercambio de los contenidos.
Por lo general, estas redes se basan en la conmutación de paquetes. Pueden clasificarse de distintas maneras de acuerdo a la arquitectura física, el tamaño y la distancia cubierta.
De acuerdo a su alcance, una red de datos puede ser considerada como una red de área personal (Personal Area Network o PAN), red de área local (LAN), red de área metropolitana (MAN) o una red de área amplia (WAN), entre otros tipos.
Fuente: definicion.de
Por lo general, estas redes se basan en la conmutación de paquetes. Pueden clasificarse de distintas maneras de acuerdo a la arquitectura física, el tamaño y la distancia cubierta.
De acuerdo a su alcance, una red de datos puede ser considerada como una red de área personal (Personal Area Network o PAN), red de área local (LAN), red de área metropolitana (MAN) o una red de área amplia (WAN), entre otros tipos.
Fuente: definicion.de
Tipos de información/sistema (digital-analógica)
Un sistema de información digital es cualquier dispositivo destinado a la generación, transmisión, procesamiento o almacenamiento de señales digitales ,es decir, tomarnunos determinados valores fijos predeterminados en momentos también discretos.
Los sistemas digitales pueden ser de dos tipos:
* Sistemas digitales combinacionales: Son aquellos en los que la salida del sistema sólo depende de la entrada presente. No necesita módulos de memoria, ya que la salida no depende de entradas previas.
* Sistemas digitales secuenciales: La salida depende de la entrada actual y de las entradas anteriores. Esta clase de sistemas necesitan elementos de memoria que recojan la información de lo "pasado" del sistema.
Un sistema es analógico cuando las magnitudes de la señal se representan mediante variables continuas. Un sistema analógico contiene dispositivos que manipulan cantidades físicas representadas en forma analógica. En un sistema de este tipo, las cantidades varían sobre un intervalo continuo de valores.
información Wikipedia
Los sistemas digitales pueden ser de dos tipos:
* Sistemas digitales combinacionales: Son aquellos en los que la salida del sistema sólo depende de la entrada presente. No necesita módulos de memoria, ya que la salida no depende de entradas previas.
* Sistemas digitales secuenciales: La salida depende de la entrada actual y de las entradas anteriores. Esta clase de sistemas necesitan elementos de memoria que recojan la información de lo "pasado" del sistema.
Un sistema es analógico cuando las magnitudes de la señal se representan mediante variables continuas. Un sistema analógico contiene dispositivos que manipulan cantidades físicas representadas en forma analógica. En un sistema de este tipo, las cantidades varían sobre un intervalo continuo de valores.
información Wikipedia
lunes, 14 de noviembre de 2011
Concepto de red informática
La red informática es un conjunto de técnicas, conexiones físicas y programas informáticos empleados para conectar dos o más computadoras. Los usuarios pueden compartir ficheros, impresoras y otros recursos, enviar mensajes electrónicos y ejecutar programas en otros ordenadores.
La finalidad principal para la creación de una red de computadoras es compartir los recursos y la información en la distancia, aumentando la velocidad de trasmición de los datos, compartiendo información y recursos.
Una red tiene tres niveles de componentes:
software de aplicaciones, software de red y hardware de red.
El software de aplicaciones está formado por programas informáticos que se comunican con los usuarios de la red y permiten compartir información (como archivos, gráficos o vídeos) y recursos (como impresoras o unidades de disco).
Un tipo de software de aplicaciones se denomina cliente-servidor. Las computadoras cliente envían peticiones de información o de uso de recursos a otras computadoras llamadas servidores, que controlan datos y aplicaciones.
El software de red consiste en programas informáticos que establecen normas, para que las computadoras se comuniquen entre sí. Enviándolos o recibiéndolos.
El hardware de red está formado por los componentes materiales que unen las computadoras. Los componentes importantes son: los medios de transmisión que transportan las señales de los ordenadores (cables,etc) y el adaptador de red, que permite acceder al medio material que conecta a los ordenadores, recibir paquetes desde el software de red a otras computadoras. La información se transfiere en forma de dígitos binarios, o bits (unos y ceros) procesados por los ordenadores.
información de Wikipedia y Terra
La finalidad principal para la creación de una red de computadoras es compartir los recursos y la información en la distancia, aumentando la velocidad de trasmición de los datos, compartiendo información y recursos.
Una red tiene tres niveles de componentes:
software de aplicaciones, software de red y hardware de red.
El software de aplicaciones está formado por programas informáticos que se comunican con los usuarios de la red y permiten compartir información (como archivos, gráficos o vídeos) y recursos (como impresoras o unidades de disco).
Un tipo de software de aplicaciones se denomina cliente-servidor. Las computadoras cliente envían peticiones de información o de uso de recursos a otras computadoras llamadas servidores, que controlan datos y aplicaciones.
El software de red consiste en programas informáticos que establecen normas, para que las computadoras se comuniquen entre sí. Enviándolos o recibiéndolos.
El hardware de red está formado por los componentes materiales que unen las computadoras. Los componentes importantes son: los medios de transmisión que transportan las señales de los ordenadores (cables,etc) y el adaptador de red, que permite acceder al medio material que conecta a los ordenadores, recibir paquetes desde el software de red a otras computadoras. La información se transfiere en forma de dígitos binarios, o bits (unos y ceros) procesados por los ordenadores.
información de Wikipedia y Terra
Suscribirse a:
Entradas (Atom)